Abstract
3D Large Language Models (LLMs) leveraging spatial information in point clouds for 3D spatial reasoning attract great attention. Despite some promising results, the role of point clouds in 3D spatial reasoning remains under-explored. In this work, we comprehensively evaluate and analyze these models to answer the research question: Does point cloud truly boost the spatial reasoning capacities of 3D LLMs? We first evaluate the spatial reasoning capacity of LLMs with different input modalities by replacing the point cloud with the visual and text counterparts. We then propose a novel 3D QA (Question-answering) benchmark, ScanReQA, that comprehensively evaluates models' understanding of binary spatial relationships. Our findings reveal several critical insights: 1) LLMs without point input could even achieve competitive performance even in a zero-shot manner; 2) existing 3D LLMs struggle to comprehend the binary spatial relationships; 3) 3D LLMs exhibit limitations in exploiting the structural coordinates in point clouds for fine-grained spatial reasoning. We think these conclusions can help the next step of 3D LLMs and also offer insights for foundation models in other modalities.
Overview
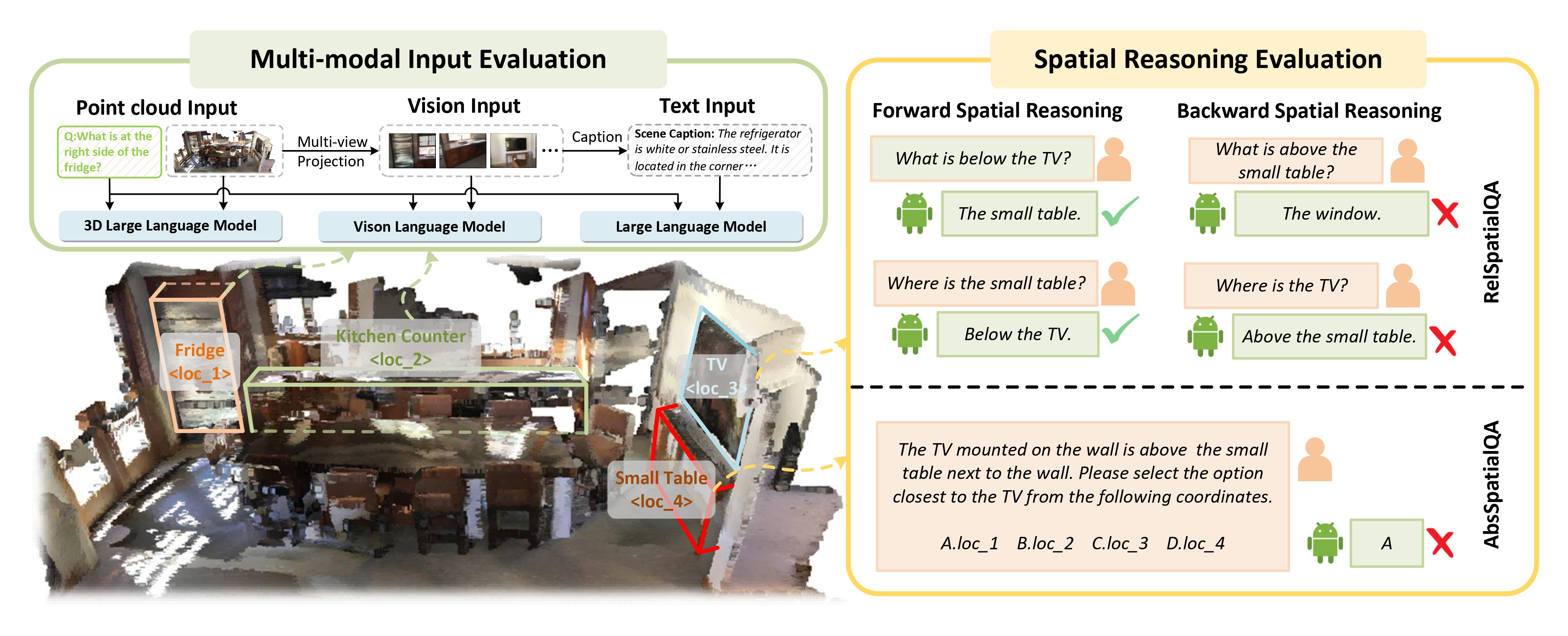
The evaluation overview of the 3D LLMs. In the Multi-modal Input Evaluation part, they are tested on 3D QA tasks with the point cloud, images, and text description inputs. Both images and text descriptions are derived from the original scene point clouds, including necessary information to answer the 3D QA. In the Spatial Reasoning Evaluation, a novel 3D QA benchmark is proposed to evaluate 3D LLMs reasoning capacities for relative spatial relationships and absolute spatial coordinates.
Multi-modal Input Generation
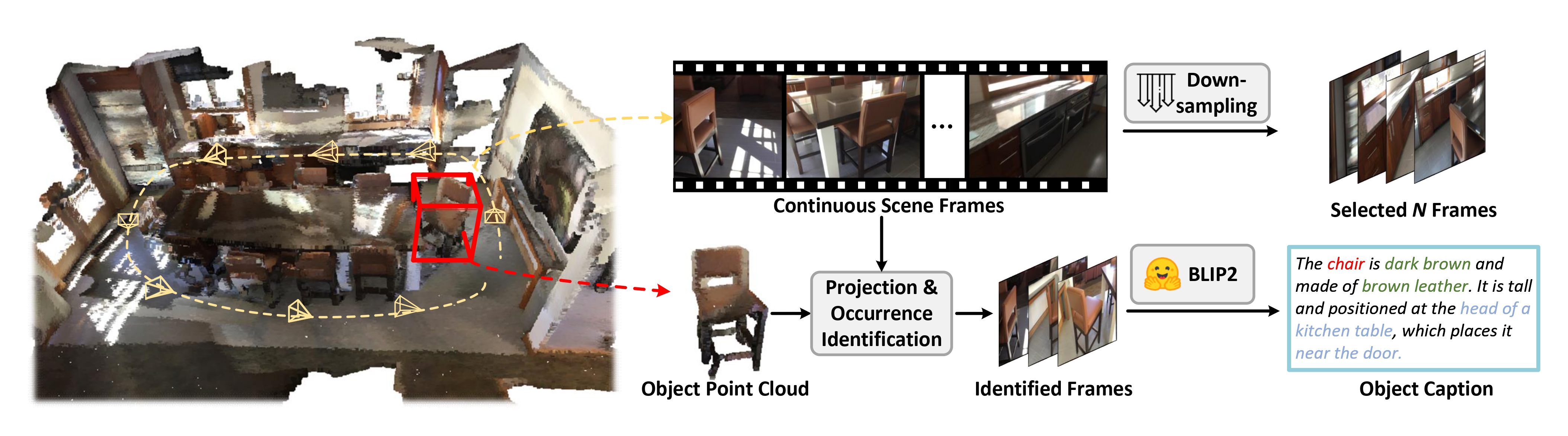
The multi-modal input data is generated from the original scene point cloud. The point clouds are projected into the continuous RGB frames and then uniformly downsample to fixed-length frames as the VLM's RGB input. The RGB frames are further captioned with off-the-shelf model to generate scene captions as the LLM's input.
ScanReQA Generation
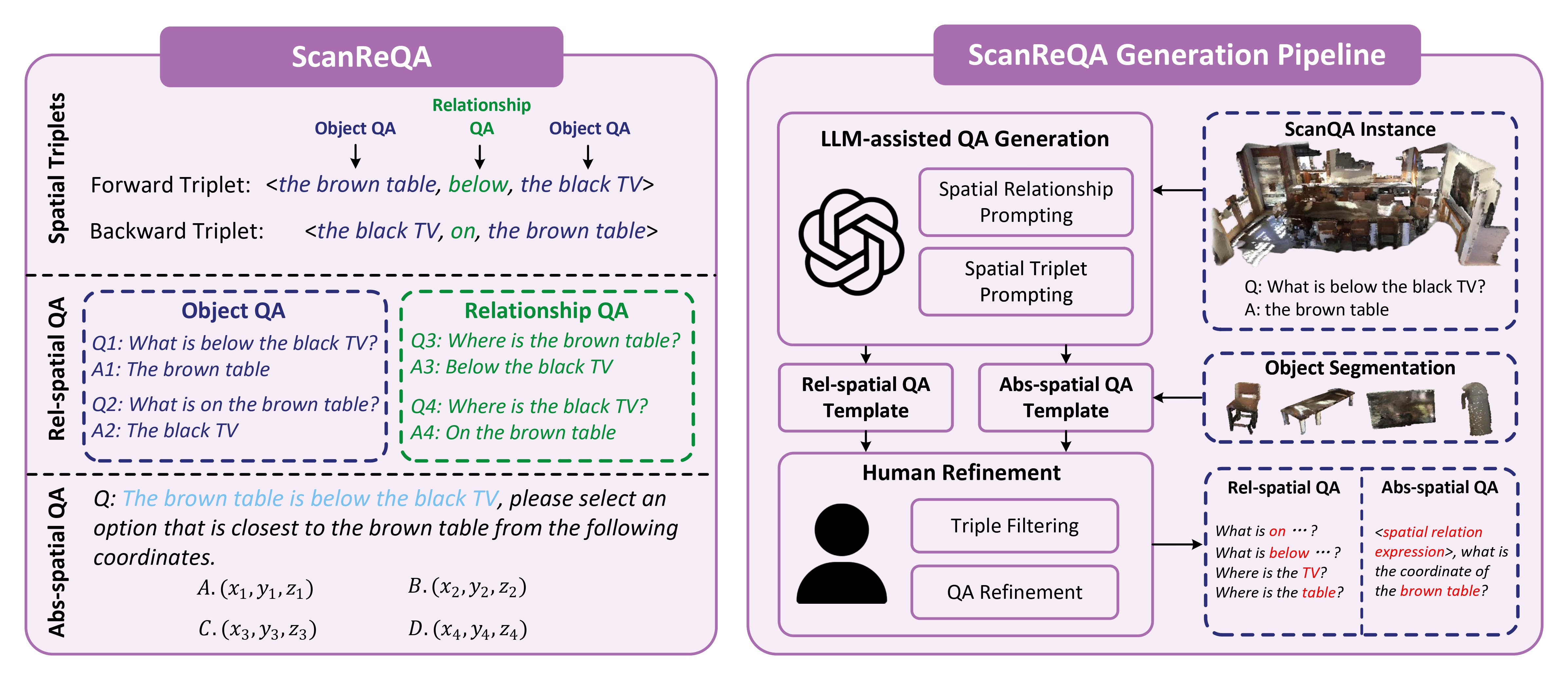
ScanReQA includes RelSpatialQA and AbsSpatialQA, which evaluate 3D LLMs' reasoning capacities for relative spatial relationships and absolute 3D coordinates. RelSpatialQA is generated from the forward and backward spatial relationship triplets, requiring the model to understand the binary spatial relationships from two opposite perspectives. AbsSpatialQA is derived from the 3D visual grounding tasks, but is more challenging. The model not only need to reason for the referred object, but also choose the object coordination from 4 options.
Experiment
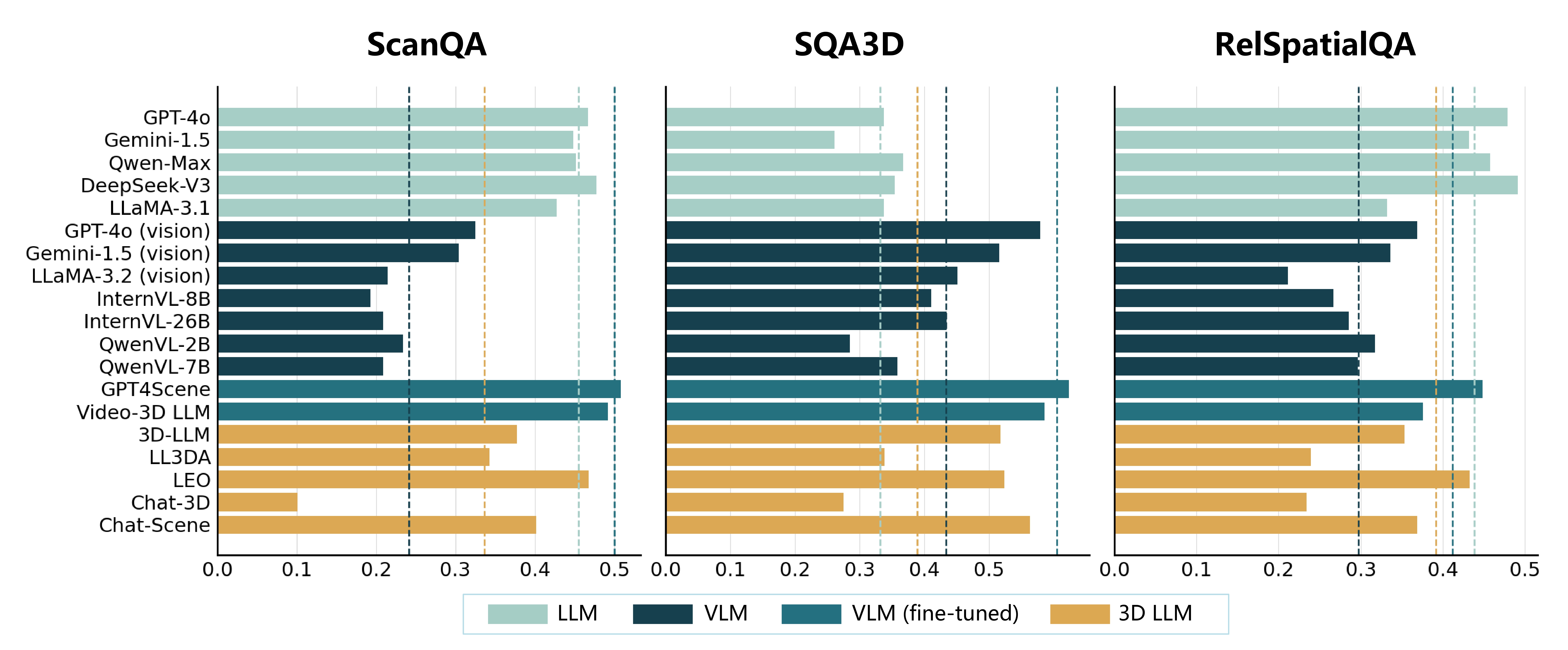
EM@1 on ScanQA, SQA3D and RelSpatialQA. 3D LLMs fail to outperform other models with vision-only or text-only inputs. The zero-shot LLMs achieve the best results on RelSpatialQA while the fine-tuned VLMs outperform other methods on ScanQA and SQA3D. In the table, all models have significantly low accuracies in binary spatial relationship reasoning and absolute coordinate prediction.
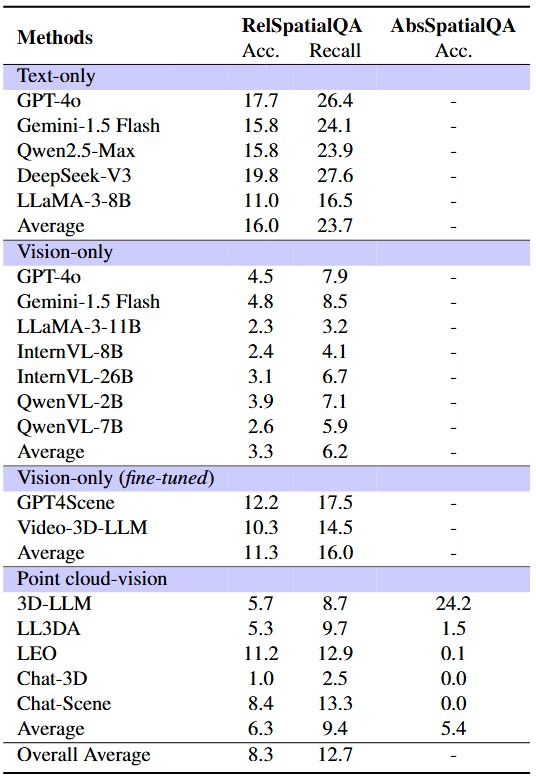
Accurary on ScanReQA
Accuracy and recall on ScanReQA (1) Overall accuracy and recall are extremely low, at only 8.3% and 12.7%, respectively; (2) LLMs achieve the highest accuracy while zero-shot VLMs achieve the lowest, with 3D LLMs falling between them; (3) Most 3D LLMs achieve near-zero accuracy on AbsSpatialQA. Even the best-performing model, 3D-LLM, only reaches the accuracy of 24.2%, which is lower than random guessing (25%).
Ablation Study
Ablations of Multi-modal Combinations. 3D LLMs with multi-view images input are more sensitive to visual modality while those with RGB point clouds are more affected by the point cloud modality. The results of Chat-Scene and Chat-3D demonstrate that the model solely relies on text input could even outperform multimodal input on 3D spatial reasoning tasks. All 3D LLMs, except 3D-LLM, achieve higher accuracy with PVTI than with PVI, indicating that redundancy in the text modality enhances spatial reasoning performance, supporting the extension of this conclusion from VLMs to 3D LLMs.
BibTeX